

WindowsでCのプログラミングを経験した人がUNIX系のシステムでプログラミングをするときに
最初に抱く疑問としてよく聞くものが1つがあります。
ユーザーがReturnキーを押すまで端末から入力を得る方法がない
ということです。
具体的にはLinuxなどのCライブラリでは
getch() … エコーバック無しで直ちに1文字分の入力を受ける
関数が使えません。
Linuxではgetch()が使えない
UNIX系OSでは端末からの入力は基本的に cooked(調理済み)モードになっています。
つまり、ユーザーが入力した raw(生の)入力はプログラムに渡される前に処理されます。
例えば バックスペースによる文字削除 などがそうです。
ユーザーがReturnキーを押してはじめて"行"が確定されてそれがプログラムに届くように
なっています。
このような仕様はキャラクタベースの操作をする上ではそれなりに使いやすい仕様では
ありますが、ユーザーがReturnキーを入力しない限り 行の終わり が現れないため
特定の用途によっては非常に厄介なことになります。
ゲームプログラムなど、行全体の入力をまたずにユーザーがキーを押すごとにそれを
取得したい場面は結構あります。
実際MicrosoftのCライブラリには エコーバック無しで文字単位に直ちに入力を得ることが
できる getch() が用意されており、Cの初学者はこの関数を使って単純な
テキストベースのゲームを作ったりします。
一方UNIX系というかANSI Cではそのような標準関数は用意されていません。
UTF-8
次に問題となるのが日本語の扱いです。
ASCIIコードは1byteにおさまるので問題ないのですが
日本語を扱うためには多バイトの文字を扱う必要があります。
多バイトを扱うための文字エンコードはいくつかありますが
今現在使いやすいものとして UTF-8 を使うことにします。
例えばUTF-8環境で "あ" を入力すると
入力バッファには 0xE3 0x81 0x82 の3byte が並びます。
何も考えず 1byteずつ取得する関数を作ってしまうとこのような
マルチバイトの入力が壊れてしまい表示がめちゃくちゃになって
しまったりするわけです。
特に UTF-8 は古臭いもので 1〜6バイト 最近のちゃんとしたもので
1〜4バイト と使用するバイト数が異なるので注意が必要です。
解決方法
以上2点を踏まえて1文字ずつデータを読みだす方法を考えます。
まず、バイト単位での読み出しに関してです。
この場合 cursesライブラリを使ってしまうという解決策は当然考えられますが
今回は趣旨に反するのでこれはなしとします。
となると、端末の設定を変更して cookedモードをやめて rawモードに
するしかありません。
端末のモード変更には以下のコードが使えます。
#include <termios.h>
#define TERM_RAW_ON 1
#define TERM_RAW_OFF 0
int termraw(int flag)
{
static struct termios t_save;
struct termios t;
if( flag == 1 )
{
if( tcgetattr(0,&t) == -1 ) return -1;
t_save = t;
t.c_iflag = ~( BRKINT | ISTRIP | IXON );
t.c_lflag = ~( ICANON | IEXTEN | ECHO | ECHOE | ECHOK | ECHONL );
t.c_cc[VMIN] = 1;
t.c_cc[VTIME] = 0;
if( tcsetattr(0, TCSANOW, &t) == -1 ) return -1;
return 0;
}else{
if( tcsetattr(0, TCSANOW, &t_save) == -1 ) return -1;
return 0;
}
}termraw(TERM_RAW_ON); で端末が rawモードに切り替わり、
termraw(TERM_RAW_OFF); で元の設定に戻ります。
RAWモードにしたままプログラムが終了しても、端末の設定は戻りませんので
その後の端末の表示がめちゃくちゃになるおそれがあります。
一度 RAW ON にしたらかならず OFFされるようにしてください。
次に入力された1バイト分のデータに関してUTF-8の場合、それ1バイトで
終わりなのか、それともまだ後ろに数バイト続いて1文字分なのかを
ちゃんと判定しなければいけません。
UTF-8でその文字が何バイトか調べるには 先頭の1バイトだけを調べれば
わかります。
具体的には
#include <stdio.h>
#include <ctype.h>
int main()
{
int i;
int chbyte;
for(i=0; i<256; i++)
{
chbyte = 0;
if(isascii(i) && isprint(i)) chbyte = 1;
if(i>=0xC2 && i<=0xDF) chbyte = 2;
if(i>=0xE0 && i<=0xEF) chbyte = 3;
if(i>=0xF0 && i<=0xF4) chbyte = 4;
printf("%d,",chbyte);
}
}このように調べられます。先頭の1バイトが↑の各範囲の時の文字の長さ
がわかるようになっています。
サンプル
以上を踏まえたサンプルコードです。
#include <stdio.h>
#include <ctype.h>
#include <termios.h>
#include <unistd.h>
#include <sys/ioctl.h>
#define TERM_RAW_ON 1
#define TERM_RAW_OFF 0
int termraw(int flag)
{
static struct termios t_save;
struct termios t;
if( flag == 1 )
{
if( tcgetattr(0,&t) == -1 ) return -1;
t_save = t;
t.c_iflag = ~( BRKINT | ISTRIP | IXON );
t.c_lflag = ~( ICANON | IEXTEN | ECHO | ECHOE | ECHOK | ECHONL );
t.c_cc[VMIN] = 1;
t.c_cc[VTIME] = 0;
if( tcsetattr(0, TCSANOW, &t) == -1 ) return -1;
return 0;
}else{
if( tcsetattr(0, TCSANOW, &t_save) == -1 ) return -1;
return 0;
}
}
static const char utf8_bytes[256] = {
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,
3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,4,4,4,4,4,0,0,0,0,0,0,0,0,0,0,0
};
int main()
{
unsigned char ch;
unsigned char exit_ch;
unsigned char escape;
int bytes;
int i;
termraw(TERM_RAW_ON);
setbuf(stdout, NULL);
escape = 0;
exit_ch = 0x03; // [Ctrl+C]
for(;;)
{
ch = getchar();
switch(ch)
{
case 0x00: printf("[Ctrl+Space]"); break;
case 0x01: printf("[Ctrl+A]"); break;
case 0x02: printf("[Ctrl+B]"); break;
case 0x03: printf("[Ctrl+C]"); break;
case 0x04: printf("[Ctrl+D]"); break;
case 0x05: printf("[Ctrl+E]"); break;
case 0x06: printf("[Ctrl+F]"); break;
case 0x07: printf("[Ctrl+G]"); break;
case 0x08: printf("[Ctrl+H/BS]"); break;
case 0x09: printf("[Ctrl+I/TAB]"); break;
case 0x0a: printf("[Ctrl+J]"); break;
case 0x0b: printf("[Ctrl+K]"); break;
case 0x0c: printf("[Ctrl+L]"); break;
case 0x0d: printf("[Enter/Ctrl+M]"); break;
case 0x0e: printf("[Ctrl+N]"); break;
case 0x0f: printf("[Ctrl+O]"); break;
case 0x10: printf("[Ctrl+P]"); break;
case 0x11: printf("[Ctrl+Q]"); break;
case 0x12: printf("[Ctrl+R]"); break;
case 0x13: printf("[Ctrl+S]"); break;
case 0x14: printf("[Ctrl+T]"); break;
case 0x15: printf("[Ctrl+U]"); break;
case 0x16: printf("[Ctrl+V]"); break;
case 0x17: printf("[Ctrl+W]"); break;
case 0x18: printf("[Ctrl+X]"); break;
case 0x19: printf("[Ctrl+Y]"); break;
case 0x1a: printf("[Ctrl+Z]"); break;
case 0x1b: escape++; break;
case 0x7f: printf("[DEL/BS]"); break;
default:
if(isascii(ch) && isprint(ch)) putchar(ch);
break;
}
switch(utf8_bytes[ch])
{
case 4: putchar(ch); ch = getchar();
case 3: putchar(ch); ch = getchar();
case 2: putchar(ch); ch = getchar();
putchar(ch);
break;
}
if(escape!=0)
{
ch = getchar();
if(ch==0x5b)
{
ch = getchar();
switch(ch)
{
case 0x32: ch = getchar();
printf("[Insert]"); break;
case 0x33: ch = getchar();
printf("[DEL]"); break;
case 0x35: ch = getchar();
printf("[PageUp]"); break;
case 0x36: ch = getchar();
printf("[PageDown]"); break;
case 0x41: printf("[up]"); break;
case 0x42: printf("[down]"); break;
case 0x43: printf("[right]"); break;
case 0x44: printf("[left]"); break;
case 0x46: printf("[END]"); break;
case 0x48: printf("[HOME]"); break;
default: printf("(ESC:%02x)",ch); break;
}
escape--;
}
}
if(ch==exit_ch){ putchar('\n'); break; }
}
termraw(TERM_RAW_OFF);
return 0;
}実行してみると
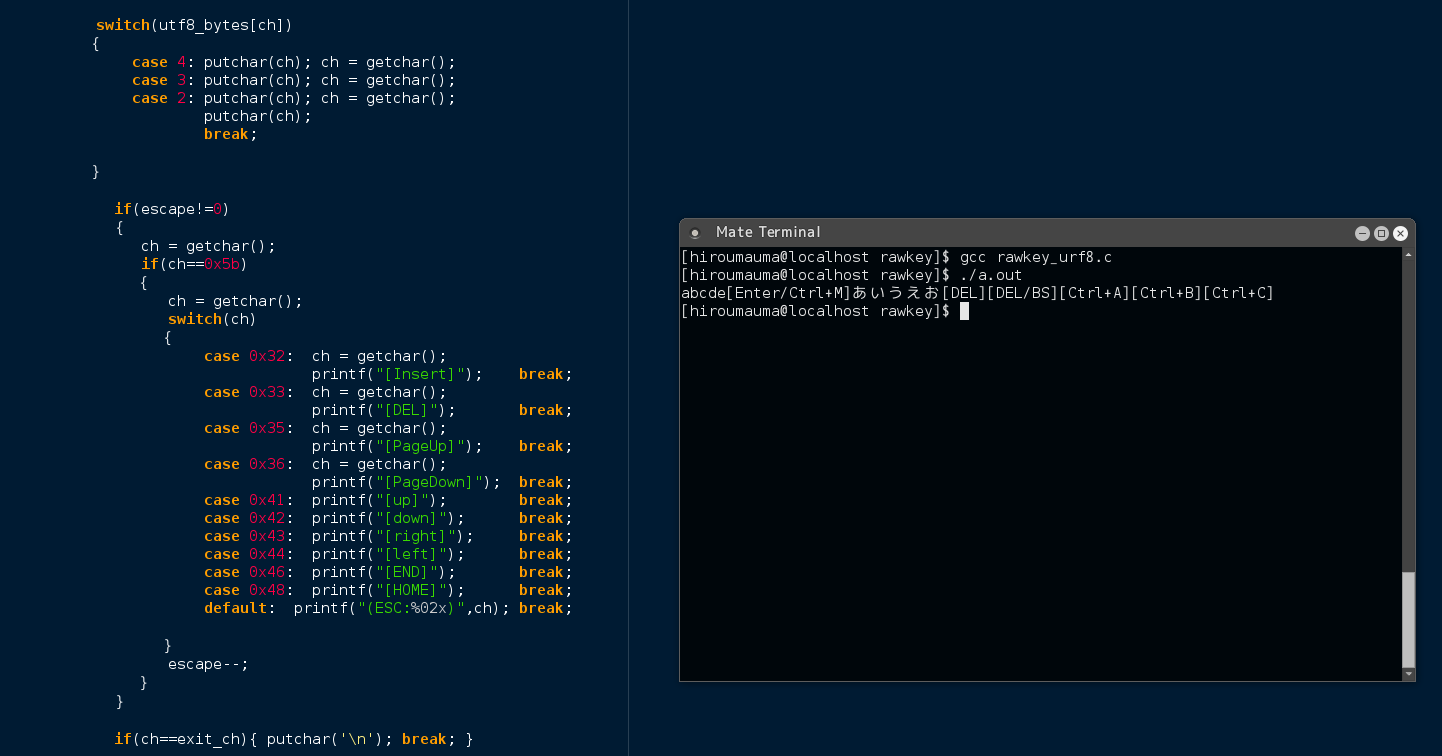
このようにReturnキーなしで順次キーの入力を受付 Ctrl+?キーや DELキーなども識別できます。
IMEをつかって日本語を入力しても問題なく反映されます。
ESCキー単体の認識だけはすこし複雑になってしまうので省略していますが、
その他の殆どのキーの入力を識別できるようにしてあります。
このままコピーして printf の代わりにフラグを立てるなどの処理に入れ替えて貰えれば
ゲームやテキストエディタの入力部分の参考になるかと思います。
少々解説すると
static const char utf8_bytes[256] = {
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,
3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,4,4,4,4,4,0,0,0,0,0,0,0,0,0,0,0
};この部分は先程のUTF-8の使用バイト数を調べる小さなプログラムの出力を
{ } で囲ったものです。
毎回
if(isascii(i) && isprint(i)) chbyte = 1;
if(i>=0xC2 && i<=0xDF) chbyte = 2;
if(i>=0xE0 && i<=0xEF) chbyte = 3;
if(i>=0xF0 && i<=0xF4) chbyte = 4;しなくても結果をテーブルにしておけば一発で結果を持ってこれます。
この手法はいろいろなところで使えます。
以上、Linuxで1文字入力を受ける方法でした。
cursesなどを使わなくても termraw() と utf8_bytes[256] さえコピーすれば
このように簡単に扱えますので getch() が無くても ビビらず ゲームコーディングできます。
ちなみにどうしても getch() が作りたい場合は
char mygetch()
{
char ch;
termraw(TERM_RAW_ON);
ch = getchar();
termraw(TERM_RAW_OFF);
return ch;
}でほぼ同じものができます。
ただ、1文字ごとに端末の設定を行ったり来たりするのはなんとなく気持ちが悪いので
Linux/Win向けに作るときは入力部分をごっそりモジュール化したほうがいいかと
思います。


コメントを追加する