

C言語でUTF8エンコーディングの文字列を扱うときに
以外に面倒なのが文字の表示幅と文字数の扱いです。
例えば strlen() は1バイト1文字として扱うので
1文字が1~4バイトのUTF8文字列を使う場合注意
しなくてはいけません。
モダンな言語ではマルチバイトな文字列を扱うための
配慮があったりなかったりしますが、C言語でこれを
解決するのは結構面倒です。
文字数について
C言語の文字列はメモリ上に並んだ文字コードの羅列にしか過ぎないので
先頭から1バイトずつよんで上手く文字ごとに切り分ける必要があります。
これについては
以前
とりあつかいました。
文字幅について
次に文字幅についてです。
East Asian Width
ここによれば
| カテゴリー | 意味 | 文字幅 |
|---|---|---|
| F | East Asian Fullwidth | 2 |
| H | East Asian Halfwidth | 1 |
| Na | East Asian Narrow | 1 |
| W | East Asian Wide | 2 |
| A | East Asian Ambiguoust | 2? |
| N | Neutral | 1 |
各文字がこのように分類されており文字幅が半角と全角の2種類あります。
特に問題なのが Aカテゴリです。
このカテゴリには 記号などが含まれていて、文字の幅が決まっていません。
日本語など全角が多い環境では記号も全角
欧州などほとんど半角の環境では記号も半角
という あいまいな(Ambigious) なグループでこれがしばしば
問題になります。
端末の設定やフォント、アプリケーションでこの文字幅の扱いが番うために
UTF8環境でカーソルの位置の制御が崩れてしまったりと結構悲惨なことに
なります。
参考
以上を踏まえて
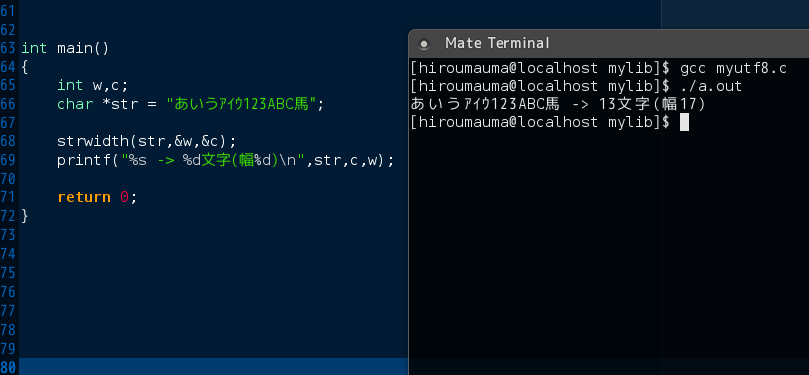
ここまでの話を抑えたうえで、あえてこういう難しいことを無視して
ひとまず日本語の文字数と表示幅を取得する小さな関数を作りました。
判定の基準は
単バイト文字(ASCII文字)は幅1
多バイト文字は基本的に幅2
ただし半角カタカナだけは幅1
以上です。
前述の通りこの判定はあまりにガバガバなので信じてはいけません。
が、大抵これでなんとかなる というものです。
ちなみに
gnome-terminal等では Aグループは半角扱い、一方フォントは全角扱い
となり、多くの場合文字が重なって描画されてしまいます。
ソフトウェア側でカーソル位置をずらしてあげるなどの対策が必要です。
#include <stdio.h>
#include <string.h>
static const char utf8_bytes[256] =
{
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,
1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,
0,0,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,2,
3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,3,4,4,4,4,4,0,0,0,0,0,0,0,0,0,0,0
};
#define utf8_nextch(X) (char *)((X) + utf8_bytes[*(unsigned char *)(X)])
int strwidth(char *str, int *width, int *count)
{
int i,j,d,c,x,bw,cw,sw;
char *p;
unsigned char tmp[8];
p = str;
x = 0;
d = 0;
c = 0;
cw = 0;
sw = 0;
for(i=0; *(str+d)!='\0' ; i++)
{
p = utf8_nextch(p);
d = (int)((unsigned long)p -(unsigned long)str);
tmp[(d-x)]='\0';
for(j=0;j<(d-x);j++){ tmp[j] = str[x+j]; }
bw = d-x;
cw = 1;
if(bw>1)
{
cw = 2;
if( tmp[0] == 0xEF && tmp[1] >= 0xBC && tmp[2] >= 0x80 )
{
cw = 1;
}
}
sw += cw;
c++;
x = d;
}
*width = sw;
*count = c;
}
int main()
{
int w,c;
char *str = "あいうアイウ123ABC馬";
strwidth(str,&w,&c);
printf("%s -> %d文字(幅%d)\n",str,c,w);
return 0;
}


コメントを追加する